Primárne databázy sa objavili v 80. a 90. rokoch 20. storočia s cieľom ukladania experimentálne odvodených údajov, ako je nukleotidová sekvencia, proteínová sekvencia alebo makromolekulárna štruktúra. Experimentálne výsledky vkladajú výskumníci priamo do databázy a údaje majú v podstate archívny charakter. Po pridelení prístupového čísla do databázy sa údaje v primárnych databázach nemenia: tvoria súčasť vedeckého záznamu. Primárne databázy sa nazývajú aj archívne databázy a obsahujú nukleotidové sekvencie, proteínové sekvencie alebo štruktúry makromolekúl.
. Existujú tri hlavné verejné databázy, ktoré uchovávajú údaje o sekvenciách nukleových kyselín a ktoré sú predkladané výskumníkmi z celého sveta. Medzi tieto databázy patrí americká databáza GenBank, európska databáza EMBL (European Molecular Biology Laboratory Data Library) a japonská databáza DDBJ (DNAData Bank of Japan), ktoré sú voľne dostupné na internete. V súčasnosti je predloženie sekvencií do GenBank, EMBL alebo DDBJ predpokladom pre publikovanie vo väčšine vedeckých časopisov, aby sa zabezpečilo bezplatné sprístupnenie základných molekulárnych údajov. Tieto tri verejné databázy úzko spolupracujú a vymieňajú si nové údaje každý deň. Spoločne tvoria medzinárodnú databázu nukleotidových sekvencií. To znamená, že po pripojení ku ktorejkoľvek z týchto troch databáz by mala mať jedna prístup k rovnakým údajom o nukleotidovej sekvencii. Aj keď všetky tri databázy obsahujú rovnaké súbory nespracovaných údajov, každá z jednotlivých databáz má mierne odlišný druh formátu údajov.
pre trojrozmerné štruktúry biologických makromolekúl existuje iba jedna centralizovaná databáza a to PDB. Táto databáza archivuje atómové súradnice makromolekúl (proteínov aj nukleových kyselín) stanovené röntgenovou kryštalografiou a NMR. Používa plochý formát súboru na vyjadrenie názvu proteínu, autorov, sekundárnej štruktúry, kofaktorov a atómových súradníc. Webové rozhranie PDB tiež poskytuje nástroje na prezeranie pre jednoduchú manipuláciu s obrázkami. Medzi primárne databázy nukleotidových sekvencií patrí GenBank, EMBL-EBI a DDBJ a aminokyselinových sekvencií (proteíny) UniProt.
Medzinárodná spolupráca databáz nukleotidových sekvencií (The International Nucleotide Sequence Database Collaboration, INSDC; http://www.insdc.org/) na zdieľaní údajov o nukleotidovej sekvencii s otvoreným prístupom po celom svete, ktorá podporuje prístup k údajom o nukleotidovej sekvencii zo všetkých kontinentov a oblastí a poskytuje široké rozpoznanie tým, ktorí generujú a zdieľajú sekvenčné údaje.
Využi pri ďalšom štúdiu tejto témy e-learningový kurz.
Štruktúra ukladaných dát v databázach
Každá z troch primárnych databáz má svoje vlastné usporiadanie formátu sekvenčného súboru. Všetky však obsahujú takmer rovnaké polia a rovnaké informácie, vďaka čomu sú vzájomne zameniteľné. Stojí za zmienku, že existuje oveľa viac formátov súborov, ktoré boli prispôsobené na špecifické účely. Tie, ktoré si priblížime v tejto kapitole predstavujú základ a umožňujú ukladať ďalšie informácie súvisiace s DNA a proteínovými sekvenciami. Každý záznam v súbore odpovedá jednej sekvencii nukleotidov alebo AMK, ktorá bola vložená do databázy alebo publikovaná v literatúre.
FASTA Formát
Textový formát na reprezentáciu buď nukleotidových sekvencií alebo aminokyselinových sekvencií, v ktorých sú páry báz alebo aminokyseliny reprezentované jednopísmenovými kódmi. Prvý riadok zvyčajne začína znakom „>“, po ktorom nasleduje identifikačný kód sekvencie a prípadne za ním nasleduje textový popis sekvencie.
• FASTA používa štandardné IUB/IUPAC kódy aminokyselín a nukleových kyselín
• Niektoré z bežných prípon súborov sú: „.fasta“, „.fa“, „.ffn“, „.frn“, „.fna“ a „.faa“
Formát FASTQ, odvodený od FASTA, je podobný textový súbor obsahujúci dôležité sekvenčné informácie. Súbory FASTQ však obsahujú podrobnosti týkajúce sa sekvenovania, z ktorého pochádzajú. Hlavný rozdiel medzi týmito dvoma súbormi je v tom, že formát FASTQ obsahuje nespracované sekvenčné informácie, konkrétne skóre kvality súvisiace so stanovením báz.
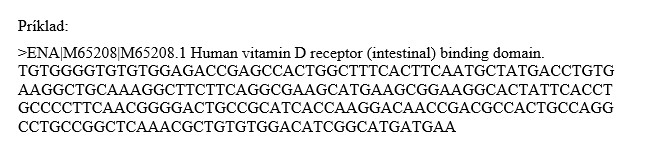
Príklad sekvencie vo Fasta formáte
GEN-BANK formát GenBank je databáza genetických sekvencií Národného inštitútu zdravia (National Institutes of Health NIH), verejná zbierka dostupných sekvencií DNA. GenBank je súčasťou International Nucleotide Sequence Database Collaboration, ktorá zahŕňa DNA DataBank of Japan (DDBJ), Európsky archív nukleotidov (ENA) a GenBank v NCBI. Formát GenBank (GenBank Flat File Format) pozostáva z anotačnej časti a sekvenčnej časti. Začiatok anotačnej časti je označený čiarou začínajúcou slovom „LOCUS“. Začiatok sekcie sekvencie je označený riadkom začínajúcim slovom „ORIGIN“ a koniec sekcie je označený riadkom iba s „//“.
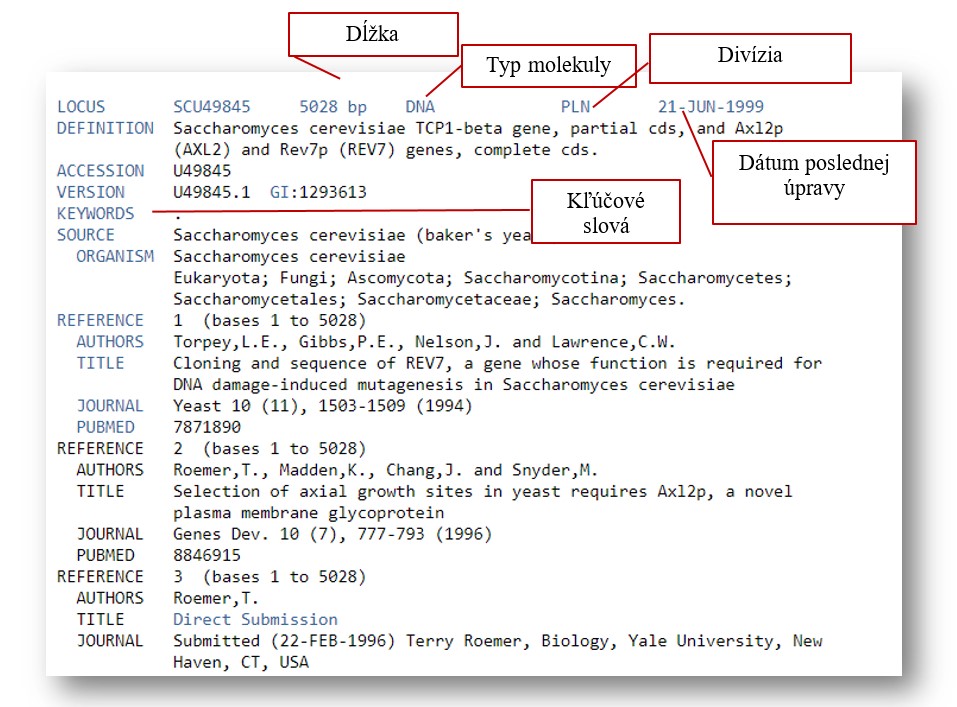
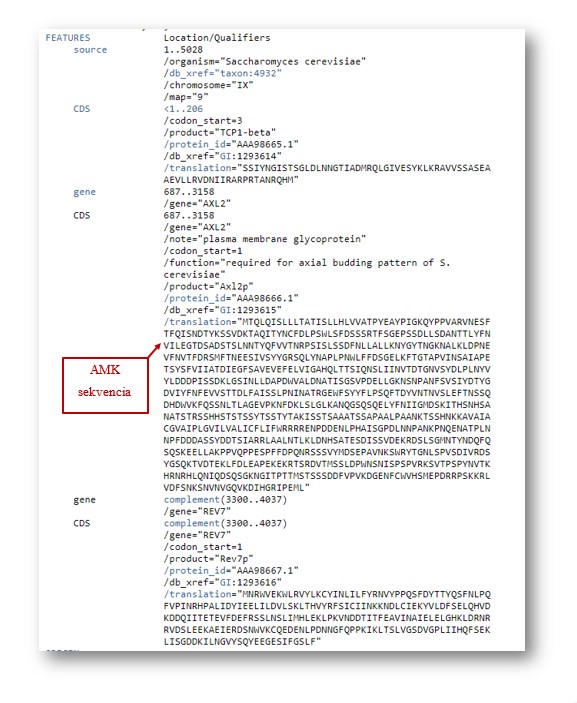

Príklad sekvencie v GenBank formáte
LOCUS: obsahuje množstvo rôznych dátových prvkov, vrátane názvu lokusu, dĺžky sekvencie, typu molekuly, divízie GenBank a dátumu modifikácie.
Názov lokusu v tomto príklade je SCU49845. Prvé tri znaky označujú organizmus; štvrtý a piaty znak sa používajú na zobrazenie iných skupinových označení, ako je napr. génový produkt; pre segmentované položky bol posledný znak jedným zo série sekvenčných celých čísel. Dané číslo musí byť jedinečné pre daný typ záznamu.
Dĺžka sekvencie počet párov nukleotidových báz (alebo aminokyselinových zvyškov) v sekvenčnom zázname. V tomto príklade je dĺžka sekvencie 5028 bp .
Divízia GenBank, do ktorej záznam patrí, je označená trojpísmenovou skratkou. V tomto príklade je divízia GenBank PLN (sekvencie rastlín, húb a rias).
Databáza GenBank je rozdelená do 18 divízií.
ACCESSION: Jedinečný identifikátor pre záznam sekvencie.
DEFINITION: Stručný popis sekvencie, ktorý záhŕňa informácie o organizme z ktorého pochádza, názov génu/proteínu, prípadne i funkciu sekvencie napr. CDS (sekvencia pre kódujúcu oblasť).
VERSION: Identifikačné číslo nukleotidovej sekvencie.
GI - "GenInfo Identifier" – identifikačné číslo sekvencie.
SOURCE: Zdroj. Informácia o názve organizmu, z ktorého sekvencia pochádza.
ORGANISM: zahŕňa vedecký názov s následným taxonomickým zatriedením.
FEATURES: (Vlastnosti) Informácia o géne, príp. o génovom produkte.
CDS: kódujúca sekvencia; oblasť nukleotidov, ktorá zodpovedá sekvencii aminokyselín v proteíne (umiestnenie zahŕňa štart a stop kodóny).
ORIGIN: Sekvenčné dáta začínajú na riadku bezprostredne pod ORIGIN (obrázok 34). Ak by sme chceli zobraziť prípadne iba uložiť údaje o sekvencii, zobrazíme si záznam vo formáte FASTA.
EMBL Formát
Predstavuje plochý formát súboru pre nukleotidové a peptidové sekvencie z databáz EMBL. Každý riadok začína dvojznakovým kódom riadku, ktorý označuje typ údajov obsiahnutých v riadku. Každý záznam v databáze obsahuje riadky rôzneho typu. Každý typ riadku má definovaný formát a obsahuje určité informácie o sekvencii pomocou špecifikovaných typov dát.
Na začiatku každého riadku záznamu je dvojznakový kód, ktorý určuje typ riadku, a teda i informácie, ktoré tento riadok obsahuje.


Príklad sekvencie v EMBL formáte
Využi pri ďalšom štúdiu tejto témy e-learningový kurz.
Túto tému nájdeš aj
v e-learningovom kurze
Prihlás sa do e-learningového kurzu a okrem plnej verzie textovej časti tejto témy získaj prístup aj k:
- prezentáciám tejto témy
- podporným materiálom k tejto téme
- možnosti otestovať svoje vedomosti
- komunikácii s autormi tejto témy
- diskusnému fóru k tejto téme
Ak ešte nemáš prístup k e-learningovému kurzu, prečítaj si, ako ho môžeš získať.

